Tienes un vector de 2048 dimensiones. Tu búsqueda vectorial tarda 500 ms. A medida que tu base de datos crece,
los gigabytes se acumulan y la velocidad cae. ¿Qué haces? ¿Cuantizar los vectores a int8?
¿Aplicar PCA para reducir dimensiones? ¿Comprar más hardware? Este es un problema muy común entre quienes
administran su infraestructura y reducir el vector sin romper la semántica no es
una opción real. O al menos, eso era cierto antes...
En este post vamos a explorar una solución elegante que cambia la forma en que pensamos en los embeddings: Matryoshka Representation Learning (MRL).
La intuición: como una foto pixelada
Pensemos por un momento en una foto de 4K de un cachorro jugando en un parque. Ves todos los detalles: las plantas, los árboles, las flores, la textura del suelo. Ahora la bajamos a 1K — sigues viendo al cachorro sin problema. La reducimos a 512 píxeles — aún reconoces al cachorro en el parque. A 100 píxeles la foto ya es un borrón, pero lo más probable es que todavía puedas distinguir que hay un perro en un fondo verde.
Ese es exactamente el concepto detrás de los Matryoshka Embeddings: la información más importante está concentrada al principio, y cada dimensión adicional solo añade detalle y granularidad.
Esto es radicalmente distinto a como funcionan los embeddings tradicionales, donde la semántica está distribuida a lo largo de todas las dimensiones de forma uniforme. Si intentaras cortar el vector, la información quedaría fragmentada, incompleta, inútil. Como intentar leer la mitad de las letras de una palabra mezcladas al azar.
Su nombre viene de las famosas Matryoshka Dolls rusas, esas muñecas de madera que contienen una versión más pequeña de sí mismas en su interior. De cierta manera, cada vector pequeño es una pequeña Matryoshka dentro de otra: el de 64 dimensiones vive dentro del de 128, que vive dentro del de 256, y así hasta el vector completo.
Truncar en tiempo de inferencia: así de simple
En inferencia, todo se reduce a un slice del vector. Si entrenaste con
embedding_64 = full_embedding[0:64]No hay que reentrenar nada, no hay que recalcular nada. Solo cortas.
El siguiente widget interactivo muestra qué nivel de calidad obtienes en cada punto de corte y qué tipo de uso es recomendable para cada uno:
Haz clic en un segmento para ver qué ocurre al truncar el vector en ese nivel
z ∈ ℝ2048 — cada banda es una representación válida por sí sola
Widget inspirado en Claude. Asumí el reto de replicar ese mecanismo de exploración visual aquí porque creo que facilitará mucho la comprensión.
¿Cómo se generan? La magia de la Loss Function
En el entrenamiento tradicional (como entrenar un BERT), la red neuronal toma una entrada de texto o imagen y la
transforma en un vector denso fijo de, digamos,
Matryoshka Representation Learning (MRL) resuelve esto con un cambio conceptualmente simple pero poderoso: en lugar de evaluar una sola loss function con el vector completo, la red evalúa múltiples loss functions, una por cada nivel dimensional dentro de un conjunto predefinido:
Gracias a este cálculo en múltiples puntos dimensionales, el modelo está obligado a lograr una loss baja incluso cuando solo dispone de 8 dimensiones. La loss total del entrenamiento MRL tiene esta forma:
Donde
Aunque todas comparten los mismos parámetros de la red, la estructura jerárquica del objetivo hace que las representaciones de baja dimensión sirvan como base, y las dimensiones posteriores añadan capacidad y granularidad sobre ella.
Por qué esto importa: FLOPs, RAM y el Memory Wall
Para entender por qué los embeddings Matryoshka son tan poderosos en producción, necesitamos hablar de cómo funciona realmente la búsqueda vectorial por dentro. Y para eso, conviene subir un poco la valla técnica.
HNSW: la búsqueda vectorial no compara contra todos los vectores
El algoritmo más común en bases vectoriales como Qdrant, Pinecone o Weaviate es HNSW (Hierarchical Navigable Small World). Contrario a lo que podría dictar la intuición, la búsqueda vectorial no compara tu query contra cada embedding de la base. Eso sería un algoritmo de fuerza bruta:
Query
↓
Comparar con vector 1
Comparar con vector 2
Comparar con vector 3
...
Comparar con vector 100,000,000Claro, esto daría siempre los mejores resultados, pero es computacionalmente inviable a escala.
HNSW organiza la base vectorial como un grafo jerárquico. Imaginemos de forma simple una base con 100K chunks:
// ejemplo ilustrativo
Nivel 5 → 5 nodos
Nivel 4 → 30 nodos
Nivel 3 → 300 nodos
Nivel 2 → 3,000 nodos
Nivel 1 → 30,000 nodos
Nivel 0 → 100,000 nodosAl recibir una query, HNSW la introduce en los nodos más altos y navega hacia abajo comparando vecinos cercanos en cada nivel, aproximándose cada vez más a los embeddings más relevantes. Al final, en lugar de visitar los 100,000 nodos, el algoritmo explora quizás 2,000 o 5,000 — y aun así da resultados de excelente calidad.
Una analogía fácil: imagina que le preguntas a alguien cuál es el mejor restaurante del mundo en 2025.
- Nivel 5 (5 personas): Una te dice "Perú".
- Nivel 4 (peruanos): Alguien te dice "Lima".
- Nivel 3 (limeños): "Miraflores".
- Nivel 2 (locales del barrio): "Calle San Martín".
- Nivel 1 (vecinos de la calle): "Ahí, esa puerta".
En el grafo HNSW ocurre exactamente eso: cada nodo te acerca un poco más a la respuesta, nivel por nivel, hasta que ya no hay a dónde seguir bajando.
FLOPs: cuánto trabajo hace el procesador por cada comparación
Un FLOP (Floating Point Operation) es una operación matemática individual con números decimales. Es la unidad que nos dice cuánto trabajo le estamos pidiendo al procesador.
La métrica reina para medir similitud entre embeddings es la similitud coseno:
Las bases de datos vectoriales como Qdrant o Pinecone normalizan los vectores al insertarlos,
lo que significa que
Para calcular este producto punto entre un vector de consulta
Si tus vectores tienen
Donde
El verdadero problema: el Memory Wall
Aquí el lector podría pensar: "¿Pero los procesadores modernos no son ultra-rápidos?". Y tienes razón — los CPUs actuales usan instrucciones SIMD que permiten multiplicar y sumar varios floats simultáneamente, ejecutando cientos de gigaFLOPS. El cálculo en sí no es el cuello de botella.
El problema viene de un lugar inesperado: la RAM y el ancho de banda de memoria.
La memoria se consume de dos formas distintas durante una búsqueda vectorial:
A. Consumo estático (ocupación de memoria)
Para que la búsqueda ANN sea rápida, todo el grafo — es decir, todos los vectores — debe estar cargado en RAM.
Con 100,000 embeddings de 2048 dimensiones en float32:
Y eso es solo los vectores puros. Los nodos del grafo también almacenan punteros a sus vecinos, lo que puede llevar el total a cerca de 2 GB de RAM estática.
B. Consumo dinámico (tráfico por el bus de memoria)
Cuando llega una consulta, el algoritmo salta de nodo en nodo. Para comparar cada nodo con la query, el
procesador debe copiar los datos desde la RAM hasta su caché (
Si el algoritmo visita 3,000 nodos por consulta:
…de datos viajando por el bus de memoria de manera concurrente. Por más rápido que sea tu procesador, este es el verdadero Memory Wall: el procesador no espera por cálculos, espera que los datos terminen su viaje desde la RAM.
Funnel Search: cómo Matryoshka resuelve ambos problemas a la vez
Ahora que entendemos el problema, veamos cómo los embeddings Matryoshka lo atacan con una técnica llamada Funnel Search (búsqueda en embudo).
La idea es simple y elegante:
-
Separar el vector en "cabeza" y "cola": El vector original de
d_{max} = 2048 se divide. Las primerasd_{short} = 128 dimensiones son la "cabeza" (head), que se almacena en el índice del grafo. Las dimensiones restantes son la "cola" (tail), guardada como metadata. - ANN con la cabeza: La exploración del grafo HNSW se realiza comparando solo los 128 primeros valores. Obtenemos un conjunto reducido de candidatos.
- Re-ranking con el vector completo: Reunimos la cabeza y la cola de los mejores candidatos (top-K), formando de nuevo el vector de 2048 dimensiones, y reclasificamos con un producto punto de precisión completa.
Comparativa de costos
Pongamos números concretos. Imaginemos que para resolver una búsqueda en el grafo HNSW, el algoritmo
necesita examinar
Sin Matryoshka — Búsqueda coseno tradicional:
Con Matryoshka — Funnel Search con
Fase 1 — ANN sobre las 128 primeras dimensiones:
Fase 2 — Re-ranking de 200 finalistas con el vector completo de 2048 dimensiones:
Totales con Funnel Search:
El mismo orden de magnitud de reducción aplica tanto al cómputo como al tráfico de memoria, que era precisamente el cuello de botella real.
La fórmula general de costo
Para que el lector pueda calcular sus propios escenarios, formalizamos el costo total de una query — FLOPs y movimiento de memoria — en una sola expresión:
Búsqueda tradicional:
Funnel Search con Matryoshka:
Donde:
V_{ANN} : nodos visitados durante la exploración del índice ANN.b : bytes por dimensión (normalmente 4 parafloat32).d_{short} : dimensiones de la cabeza (el vector reducido Matryoshka).d_{max} : dimensiones del vector completo, usado para el re-ranking.K : número de candidatos finales para reclasificar.
Nota: usamos la aproximación
Las métricas del paper: de la teoría a los números reales
Hasta aquí hemos construido el caso teórico de MRL con fórmulas y razonamientos propios. Es momento de pisar tierra firme y revisar lo que los autores del paper —Kusupati et al., NeurIPS 2022— midieron en sus propios experimentos. Revisaremos tres resultados concretos.
Antes de entrar en los gráficos, vale la pena contextualizar las arquitecturas que aparecen en ellos. Soy el primero en admitir que, debido a mi mayor exposición a temas de 2026, las siguientes no eran muy cercanas a mí y tuve que hacer un poco de indagación, aquí un mini-resumen para que el lector no tenga que pasar por ello:
- ResNet-50 (visión clásica): red neuronal convolucional que analiza imágenes detectando patrones pixel a pixel en capas sucesivas. Genera un vector de salida de 2048 dimensiones.
- ViT (Vision Transformer): en lugar de convoluciones, divide la imagen en parches y los procesa como piezas de un rompecabezas, usando atención para relacionarlos entre sí. Su vector de salida tiene 768 dimensiones.
- BERT: probablemente el más conocido de los tres. Es el modelo de Google para comprensión de texto, también basado en atención. Su salida, al igual que ViT, es de 768 dimensiones.
- ImageNet: conjunto de datos de imágenes etiquetadas con más de 1 millón de fotos categorizadas (objetos, animales, paisajes, etc.). Cuando ves resultados de investigación hablando de ImageNet-1K, se refieren a la versión con 1,000 categorías; ImageNet-4K tiene 4,000.
La razón para presentar estas tres arquitecturas es la misma que motiva a los autores: demostrar que MRL funciona bien independientemente del modelo base. Ya sea una red convolucional clásica como ResNet-50 o un Transformer moderno, la estructura Matryoshka se adapta sin fricciones.
Representation Learning: ¿se pierde calidad al anidar vectores?
La pregunta central que este experimento responde es sencilla pero fundamental:
Si obligamos a un modelo a meter vectores pequeños dentro de vectores grandes (como muñecas rusas), ¿vamos a romper el modelo o va a perder precisión en comparación con un modelo normal?
Para responderla, los autores entrenaron una ResNet-50 con MRL sobre el conjunto de dimensiones
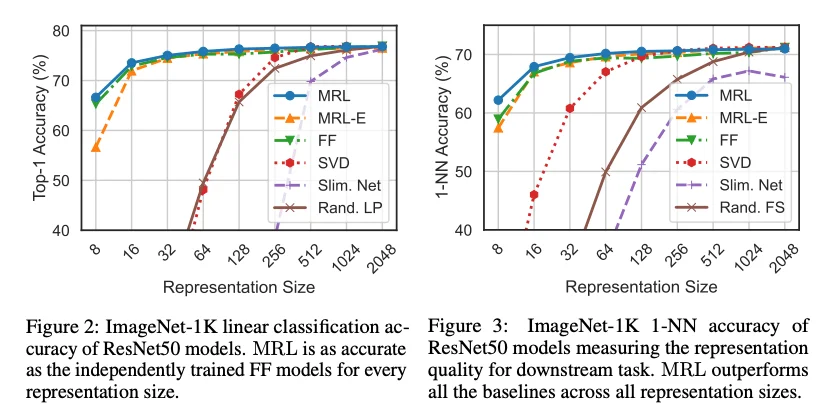
Gráfico izquierdo — Clasificación lineal (top-1 accuracy):
El eje X recorre las dimensiones desde 8 hasta 2048; el eje Y mide la calidad de la representación en términos de precisión en clasificación lineal sobre ImageNet-1K:
- La curva azul —MRL— arranca naturalmente baja en 8 dimensiones y sube con fluidez a medida que crecen las dimensiones.
- Lo que llama la atención es la velocidad con que satura: a partir de las 32 dimensiones, las mejoras son pequeñas, como afinamientos.
La curva verde, etiquetada como Fixed Feature (FF), es el baseline más exigente: representa modelos entrenados de cero, individualmente, para cada tamaño de vector. Es el ideal teórico. Y sin embargo, la curva azul de MRL lo iguala o supera en prácticamente todos los puntos. Que un único modelo entrenado de forma conjunta supere a modelos especializados para cada tamaño es, en sí mismo, uno de los resultados más interesantes del paper.
Gráfico derecho — 1-NN (1-Nearest Neighbor):
Este gráfico es el más relevante para búsqueda vectorial. El 1-NN mide qué tan bien se agrupan los vectores similares en el espacio de representación: perros cerca de perros, autos cerca de autos. Es, en esencia, la calidad de recuperación en un escenario de retrieval puro.
El hallazgo más notable aparece en las dimensiones bajas —16, 32 y 64—: la curva de MRL supera al baseline de vectores tradicionales.
Adaptive Retrieval: Funnel Search en la práctica
Este experimento es la validación empírica de todo lo que calculamos en la sección anterior. Los autores implementaron Funnel Search con sus propios modelos MRL y midieron calidad y costo computacional real. Para leer los gráficos correctamente, conviene tener claras las variables:
-
D_s (Shortlist Dimension): la dimensión reducida que se usa en la primera pasada de búsqueda sobre el grafo HNSW. En las leyendas, son los puntos que van del azul claro al oscuro. -
D_r (Reranking Dimension): la dimensión completa con la que se reordenan los candidatos que pasaron el primer filtro. - mAP@10 (eje Y): Mean Average Precision en los diez primeros resultados. Es la métrica estándar para evaluar la calidad de recuperación en motores de búsqueda y pipelines RAG. Un valor más alto indica resultados más relevantes.
-
MFLOPs/Query (eje X): millones de operaciones matemáticas por consulta, en escala
logarítmica (
10^2,\,10^3,\,10^4 ). Desplazarse hacia la izquierda en este eje significa que el sistema es exponencialmente más barato y rápido.
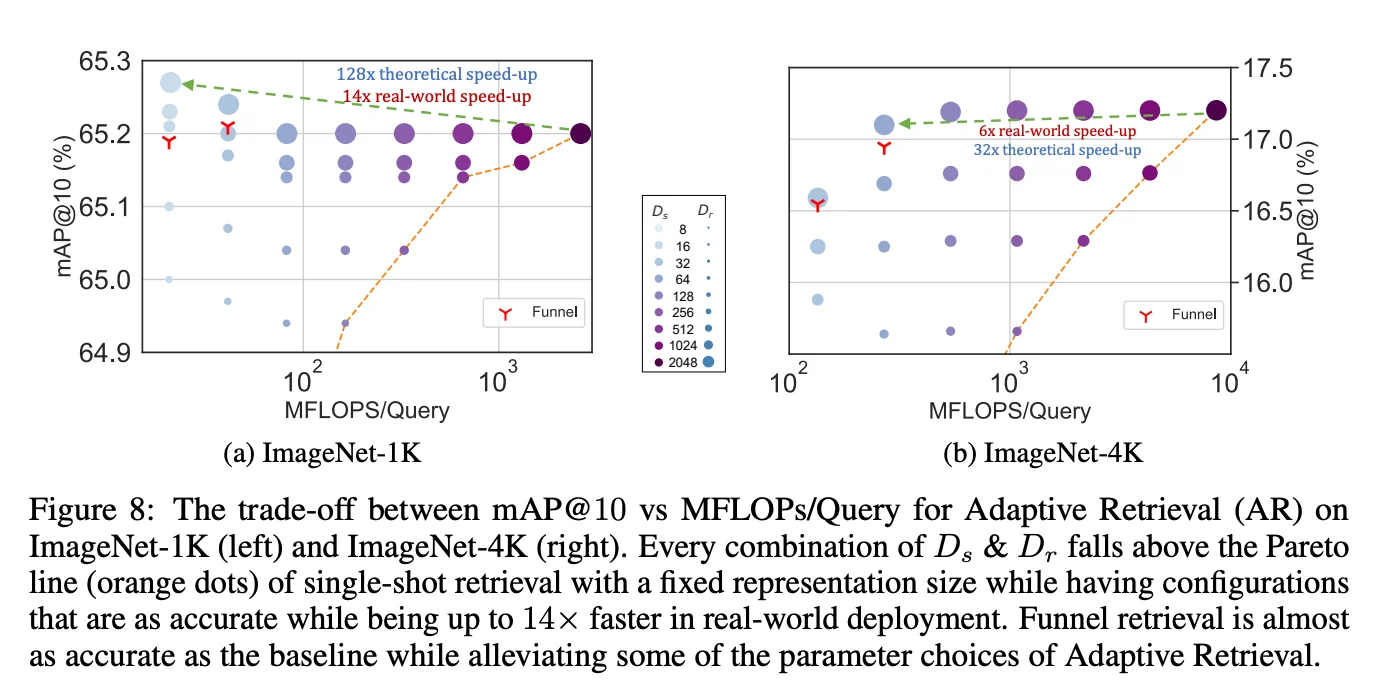
(a) ImageNet-1K:
La línea naranja representa embeddings tradicionales sin MRL. Hacia la izquierda del eje X, donde los FLOPs son bajos, dim bajos, la calidad de recuperación es pobre. La línea termina donde empieza a ser comparable con MRL: usando todos los FLOPs posibles, con el vector completo.
Los puntos azules y morados son MRL:
-
Punto más a la derecha (morado esquina): corresponde a buscar directamente con las 2048 dimensiones completas.
Máxima precisión (≈65.2% mAP@10), máximo costo (
10^3 MFLOPs). -
Punto más a la izquierda (azul opaco arriba - Funnel Search): marcado con el indicador de una Y roja,
usa
D_s = 16 para la exploración del grafo yD_r = 2048 para el re-ranking de los 200 mejores candidatos. - El resultado: una precisión de ≈65.3% mAP@10 —prácticamente idéntica— pero con una reducción teórica de 128× en FLOPs que, como veremos en las métricas más adelante, en hardware real se traduce en un speedup de 14× en tiempo de pared (wall-clock time).
(b) ImageNet-4K:
Con un dataset cuatro veces más denso, la historia se repite con un matiz esperable: el espacio de
representación es más complejo y un filtro inicial de solo 16 dimensiones no es suficiente para discriminar
candidatos relevantes (Notarán la primera Y roja con un puntaje bajo). Los autores ajustaron a
Mapas de calor Grad-CAM: Matryoshka visto desde adentro
Cerramos esta revisión con lo que, personalmente, es la parte más bella para entender de forma intuitiva qué ocurre dentro de un modelo MRL.
El escenario es el siguiente: una ResNet-50 entrenada con MRL sobre ImageNet-1K genera embeddings de 2048
dimensiones con estructura Matryoshka. Recordemos que ImageNet tiene sus labels Ground truth.
Sobre ese embedding, un clasificador lineal produce un vector de probabilidades sobre las 1,000 clases posibles
—algo como [perro: 0.01, gorro de ducha: 0.85, bolsa de plástico: 0.12…].
Aquí entra la Grad-CAM (Gradient-weighted Class Activation Mapping). A diferencia de un clasificador que solo lee el embedding final, Grad-CAM retrocede desde la predicción hasta las activaciones internas de la red y se pregunta: ¿qué píxeles de la imagen fueron los que más influyeron en la activación de las neuronas que generaron este vector embedding y posterior predicción? El resultado es un mapa de calor superpuesto sobre la imagen original.
Lo que los autores hicieron fue generar estos mapas para cada corte dimensional —8, 16, 32, 64…— y observar cómo evoluciona la atención del modelo a medida que se le dan más dimensiones para trabajar.
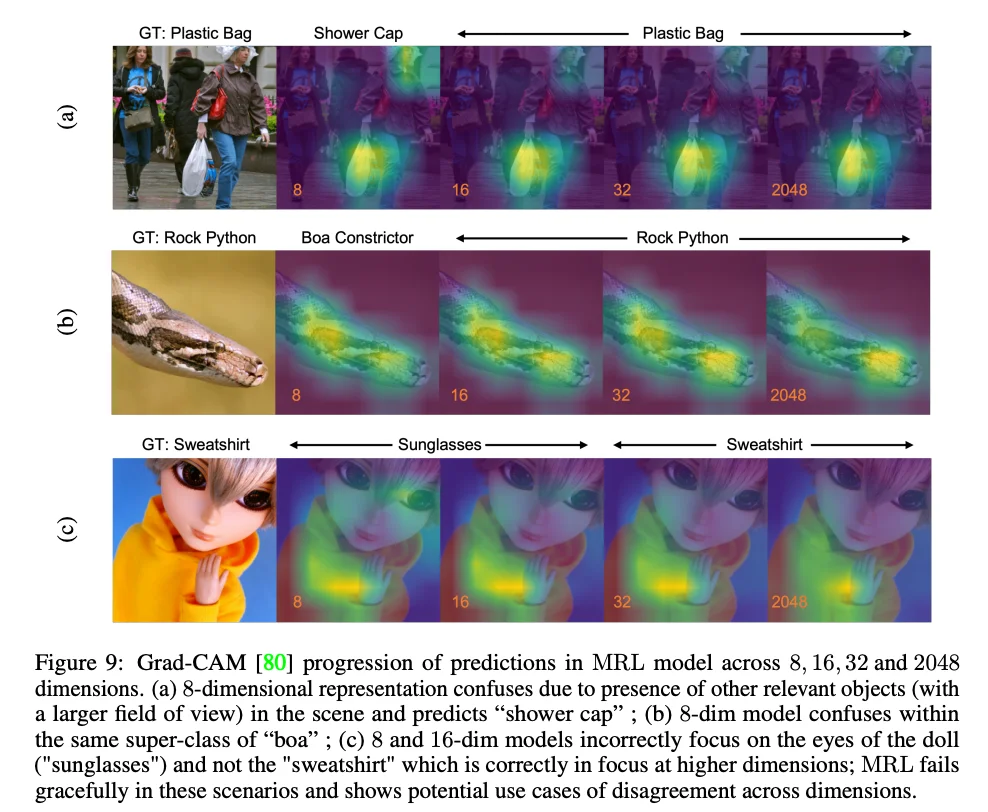
Caso (a) — La mujer con la bolsa de plástico
Ground truth: plastic bag.
Con solo 8 dimensiones, el modelo concentra su atención en la cabeza —el gorro de ducha— y clasifica shower cap. Es técnicamente incorrecto, pero no es una predicción disparatada: el modelo está mirando el objeto más prominente en el frame. A partir de las 16 y 32 dimensiones, el mapa de calor migra con claridad hacia la bolsa blanca que cuelga de la mano. La atención se refina, y la predicción converge en plastic bag.
Caso (b) — La serpiente
Ground truth: rock python.
Con 8 dimensiones, el modelo predice boa constrictor. Incorrecto en especie, pero la superclase —serpiente— ya está capturada. Con 16 dimensiones en adelante, la atención se afina sobre los patrones específicos de la piel y la predicción converge hacia rock python.
Caso (c) — La figura con sudadera amarilla
Ground truth: sweatshirt.
En 8 y 16 dimensiones, el modelo fija la atención en los ojos grandes y caricaturescos de la figura y predice sunglasses. Es el objeto más visualmente saliente en esa resolución semántica. A partir de las 32 dimensiones, el mapa de calor se desplaza al pecho y la predicción cambia a sweatshirt —la etiqueta correcta.
Los tres casos cuentan la misma historia: la estructura interna de MRL replica, de forma emergente, la percepción visual jerárquica. Las dimensiones bajas capturan categorías gruesas, casi siempre semánticamente coherentes aunque no del todo precisas. Cada dimensión adicional no contradice lo anterior —lo afina, lo granulariza, y lo llevo un poquito mas cerca a la verdad...
Funnel Search en código
Se deja a disposición un repositorio público con una implementación práctica de la lógica de re-ranking basada en Funnel Search — parte del repositorio de código abierto de este blog.
Código para Funnel Searchdocker-compose.ymlpara levantar Qdrant localmente, más scripts de ingestión y limpieza de datos.- Script de búsqueda inspirado en Funnel Search usando Voyage AI para los embeddings — requiere API key gratuita disponible en su página: voyageai.com
Conclusiones y ... ¿Cuándo usar Matryoshka y cuándo no?
Mi recomendación es clara: usá Matryoshka en producción. Y más específicamente, en cualquier contexto donde la escala sea una variable real — alta concurrencia, bases vectoriales que crecen con el tiempo, entornos con memoria limitada, sistemas que atienden múltiples clientes con distintos requisitos de latencia, o pipelines donde cada milisegundo importa.
En particular, por las siguientes razones:
- Flexibilidad ante el crecimiento: Hoy puedes poner 1024 dimensiones, y dentro de una semana darte cuenta de que tienes un overhead de almacenamiento o latencia inesperado. Con embeddings Matryoshka, no tienes que regenerar todos los vectores — solo cambias el punto de corte.
- El Funnel Search no se puede replicar sin MRL: La separación cabeza/cola es posible precisamente porque las primeras dimensiones son semánticamente ricas por diseño. Con embeddings tradicionales, truncar el vector destruye la semántica. Con Matryoshka, puedes decidir usarlo o no.
- Un solo modelo, múltiples perfiles de latencia: El mismo modelo puede servir a distintos clientes con distintos requisitos: uno que necesita máxima velocidad usa 64 dim, otro que necesita máxima precisión usa 2048 dim. Sin reentrenamiento, sin modelos separados.
- Mejor calidad que los embeddings tradicionales, incluso en dimensiones bajas: Esto no es intuición — lo vimos en los gráficos del paper. En el experimento de 1-NN, los vectores MRL superan al baseline tradicional en las dimensiones reducidas (16, 32, 64). El modelo pequeño de Matryoshka hereda la inteligencia de las dimensiones mayores; el vector tradicional recortado, no.
- Reducción de costos de infraestructura sin sacrificar precisión: Como vimos en Funnel Search, una reducción de ~91% en FLOPs y tráfico de memoria se traduce en speedups reales de hasta 14×. Menos instancias, menos RAM, menos factura de nube — sin que el usuario note la diferencia en calidad.
- Compatible con cualquier arquitectura base: El paper lo demostró con ResNet-50, ViT y BERT. MRL no es una técnica atada a un modelo específico — se aplica sobre lo que ya tenés.
¿Y cuándo no usarlo? Honestamente, me resulta difícil argumentar en contra de los embeddings Matryoshka en sí. Si tu base vectorial ya está en producción, funciona bien, y migrar supondría regenerar miles de vectores sin un beneficio inmediato y medible — entonces no tiene sentido hacerlo por hacerlo. Cambiar por cambiar es caro en tiempo de infraestructura y testing.
Donde sí vale la pena hacer una distinción más fina es en el Funnel Search específicamente. Hice una prueba superficial con ~80K documentos en local: 20 queries, midiendo latencia promedio por búsqueda. Los resultados:
- Búsqueda tradicional: ~15 ms / query
- Funnel Search: ~18 ms / query — un 0.83× speedup, es decir, más lento.
- Base de datos usada: Qdrant, un motor vectorial escrito en Rust y mi base favorita..., diseñado específicamente para búsqueda ANN de alta performance con soporte nativo de HNSW y cuantización. Es uno de los más eficientes disponibles — otras bases vectoriales construidas sobre capas más pesadas probablemente si lleguen a tener más problemas.
Las razones son directas:
- El memory wall no aparece con datasets pequeños. Con 80K vectores en local, todo el índice cabe en la caché del procesador. Sin cache misses reales, no hay cuello de botella de memoria que el Funnel Search pueda resolver.
- El re-ranking tiene su propio costo. Después del ANN hay que recuperar los vectores completos, reconstruirlos y calcular los dot products del re-ranking — pasos que la búsqueda tradicional no tiene. Con pocos candidatos, ese overhead domina.
- La ganancia requiere escala y concurrencia real. El paper mide speedups con millones de vectores y consultas simultáneas. A esa escala el índice ya no cabe en caché y cada salto del grafo provoca un cache miss real — ahí es donde el Funnel Search recupera todo su ventaja.
Si no estás en ese escenario, la búsqueda normal con Matryoshka sería mi recomendación.
Fuera de eso, si decides no usar Matryoshka (lo cual también sería difícil, considerando que los principales modelos de embedding ya lo incluyen por defecto: OpenAI text-embeddings, Gemini Embedding 2, Voyage AI…), probablemente seas el tipo de persona que rechaza el aire acondicionado en verano.
Fuentes
- Kusupati et al. (last revised Feb 2024). Matryoshka Representation Learning. NeurIPS 2022. PDF oficial NeurIPS · arXiv:2205.13147
- Liu, Z., et al. (2025). Matryoshka Re-Ranker: A Flexible Re-Ranking Architecture With Configurable Depth and Width. arXiv:2501.16302
- CIKM 2025 Proceedings. cikm2025.org
- Qdrant documentation — Matryoshka / binary quantization
- Sentence Transformers. Matryoshka Representation Learning. Ejemplo de entrenamiento MRL
- VoyageAI. Voyage 4 Nano — modelo de embeddings ligero.
- Cautis, S. FLOPs and About: A Guide. arXiv:1111.0688 — fundamentos de operaciones floating-point y tráfico de memoria.
- Bernstein, M. Matrix-Vector Multiplication Walkthrough. mbernste.github.io — explicación visual de operaciones matriciales.